La biblioteca de clases del .NET Framework es, como su propio nombre indica, una biblioteca de clases... (Vaya descubrimiento, ¿eh?) Vaaaale... me explicaré mejor. Si has programado en C++ conocerás la MFC (Microsoft Foundation Classes), o la OWL de Borland (Object Windows Library). Si no eres programador de C++ y/o no las conoces, pues me has hecho la puñeta... A volver a empezar. Veamos, la biblioteca de clases del .NET Framework te ofrece un conjunto de clases base común para todos los lenguajes de código gestionado. O sea, si, por ejemplo, quieres escribir algo en la pantalla, en Visual Basic sería así:
Console.WriteLine(“Algo”)
En C# sería así:
Console.WriteLine(“Algo”);
En C++ gestionado sería así:
Console::WriteLine(“Algo”)
Como ves, es igual (o casi igual) en todos los lenguajes. En C++ hay que poner :: en lugar de un punto por una cuestión meramente sintáctica propia de este lenguaje para separar el nombre de una clase de uno de sus miembros. Ojo, no quiero decir que todos los lenguajes sean iguales, no, sino que todos usan la misma biblioteca de clases o, dicho de otro modo, todos usan las mismas clases de base. Ya sé, ya sé: ahora estaréis pensando que, si esto es así, todos los lenguajes tienen la misma capacidad. Bueno, pues es cierto, aunque sólo relativamente, pues no todos los lenguajes implementan toda la biblioteca de clases completa, ya que basta con que el compilador se ajuste a los mínimos que exige el CLS.
Por otro lado, la compilación de un programa gestionado por el CLR no se hace directamente a código nativo, sino a un lenguaje, más o menos como el ensamblador, llamado MSIL (Microsoft Intermediate Language). Después es el CLR el que va compilando el código MSIL a código nativo usando lo que se llaman los compiladores JIT (Just In Time). Ojo, no se compila todo el programa de golpe, sino que se van compilando los métodos según estos se van invocando, y los métodos compilados quedan en la caché del ordenador para no tener que compilarlos de nuevo si se vuelven a usar. Hay tres tipos de JIT, pero ya los trataremos más adelante, pues creo que será más oportuno. ¿Se trata entonces de lenguajes compilados o interpretados? Pues me has “pillao”, porque no sabría qué decirte. No es interpretado porque no se enlaza línea por línea, y no es compilado porque no se enlaza todo completo en el momento de ejecutar. Llámalo x.
BASES SINTÁCTICAS DE C#
Ahora sí, ahora por fin empezamos a ver algo de C#. Agárrate bien, que despegamos.
Si vienes de programar en otros lenguajes basados en el C, como C++ o Java, o incluso en el propio C, te sentirás cómodo enseguida con C#, ya que la sintaxis es muy parecida. Si vienes de programar en otros lenguajes de alto nivel, como Visual Basic, Delphi, PASCAL o COBOL, por ejemplo, o incluso si no conoces ningún lenguaje de programación, no te dejes asustar. Leer y entender programas escritos en alguno de estos últimos lenguajes es algo bastante fácil, incluso si no habías programado nunca. Sin embargo, leer programas hechos en C, C++, Java o C# puede resultar muy intimidatorio al principio. Encontrarás llaves por todas partes, corchetes, paréntesis, operadores extraños que nunca viste en otros lenguajes, como |, ||, &, &&, !, !=, = =, <<, >>, interrogantes, dos puntos, punto y coma y cosas así. Incluso verás que algunas veces la misma instrucción parece hacer cosas completamente distintas (aunque en realidad no es así). Ya no te quiero contar cuando escribas tu primer programa en C#: posiblemente tengas más errores que líneas de programa. Sin embargo, repito, no te dejes asustar. Aunque es un poco confuso al principio verás cómo te acostumbras pronto. Además, el editor de Visual Studio.NET te ayuda mucho a la hora de escribir código, ya que cuando detecta que falta algo o hay alguna incoherencia te subraya la parte errónea en rojo o en azul, tal y como hace el MS-Word, por ejemplo, cuando escribes una palabra que no tiene en el diccionario ortográfico, o cuando lo escrito es incorrecto gramaticalmente.
Como decía, la sintaxis de C# es muy parecida a la de C, C++ y, sobre todo, Java. Para diseñar este lenguaje, Microsoft ha decidido que todo lo que se pudiera escribir como se escribe en C era mejor no tocarlo, y modificar o añadir únicamente aquellas cosas que en C no tienen una relativa equivalencia. Así, por ejemplo, declarar una variable o un puntero en C# se escribe igual que en C:
int a;
int* pA;
No obstante, hay que prestar atención especial a que, aunque un código sea sintácticamente idéntico, semánticamente puede ser muy distinto, es decir: mientras en C la una variable de tipo int es eso y nada más, en C# una variable de tipo int es en realidad un objeto de la clase System.Int32 (ya dijimos en la introducción que en C# todo es un objeto salvo los punteros). En resumen, las diferencias más importantes entre C y C# no suelen ser sintácticas sino sobre todo semánticas.
Bien, una vez aclarado todo esto, podemos seguir adelante. Primera premisa: en C# todas las instrucciones y declaraciones deben terminar con ; (punto y coma), salvo que haya que abrir un bloque de código. Si programas en Pascal o Modula2 dirás: “Hombre, claro”, pero si programas en Visual Basic no te olvides del punto y coma, pecadorrrrrr. ¿Por qué? Porque, al contrario que en Visual Basic, aquí puedes poner una instrucción que sea muy larga en varias líneas sin poner ningún tipo de signo especial al final de cada una. Es cuestión de cambiar el chip. Fíjate en esta simulación:
A = Metodo(argumento1, argumento2, argumento3, argumento4
argumento5, argumento6, argumento7, argumento8);
El compilador entiende que todo forma parte de la misma instrucción hasta que encuentre un punto y coma.
¿Y qué es un bloque de código? Pues vamos con ello. Un bloque de código es una parte del mismo que está "encerrado" dentro de algún contexto específico, como una clase, un método, un bucle... Veamos un ejemplo muy significativo. El siguiente fragmento de código es una función escrita en Visual Basic:
Public Function EsMayorQueCero(numero as Integer) as Boolean
If numero > 0 Then
EsMayorQueCero = True
End If
End Function
En esta función podemos encontrar dos bloques de código: el primero de ellos es todo el que está dentro del contexto de la función, es decir, entre la línea donde se declara la función (Public Function EsMayorQueCero...) y la línea donde termina dicha función (End Function). El otro bloque está dentro del contexto del If, y está compuesto por la única línea que hay entre el principio de dicho contexto (If numero > 0 Then) y la que indica el final del mismo (End If). Por lo tanto, como puedes ver, en Visual Basic cada bloque empieza y termina de un modo distinto, dependiendo de qué tipo de bloque sea, lo cual hace que su legibilidad sea muy alta y sencilla. Veamos ahora su equivalente en C# (y no te preocupes si no entiendes el código, que todo llegará):
public bool EsMayorQueCero(int numero)
{
if (numero>0)
{
return true;
}
return false;
}
En este caso, los bloques de código están muy claramente delimitados por las llaves, pero como puedes apreciar, ambos bloques están delimitados del mismo modo, es decir, ambos se delimitan con llaves. Además, fíjate en que detrás de la línea en que se declara el método no está escrito el punto y coma, igual que en el if, lo cual quiere decir que la llave de apertura del bloque correspondiente se podía haber escrito a continuación, y no en la línea siguiente. Según está escrito, es fácil determinar cuáles son las llaves de apertura y cierre de un bloque y cuáles las del otro. Sin embargo, si hubiésemos quitado las tabulaciones y colocado la llave de apertura en la misma línea, esto se habría complicado algo:
bool EsMayorQueCero(int numero) {
if (numero>0) {
return true;
}
return false;
}
Si, además, dentro de este método hubiera tres bucles for anidados, un switch, dos bucles While y cuatro o cinco if, unos dentro de otros, con algún que otro else y else if, pues la cosa se puede convertir en un galimatías de dimensiones olímpicas. De ahí la importancia de tabular correctamente el código en todos los lenguajes, pero especialmente en los lenguajes basados en C, como el propio C, C++, Java y C#, ya que así será fácil ver dónde empieza y dónde termina un bloque de código. Digo esto porque, a pesar de que Visual Studio.NET pone todas las tabulaciones de modo automático, siempre puede haber alguno que las quite porque no le parezcan útiles. ¡NO QUITES LAS TABULACIONES! ¿Cómo? ¿Que podría haber abreviado mucho el código en este ejemplo? Sí, ya lo sé. Pero entonces no habríamos visto bien lo de los bloques. Un poco de paciencia, hombre...
Los programas escritos en C# se organizan en clases y estructuras, de modo que todo el código que escribas debe ir siempre dentro de una clase o bien de una estructura, salvo la directiva using. Por eso las funciones ahora se llaman métodos, porque serán métodos de la clase donde las pongas, y las variables y constantes (dependiendo de dónde se declaren) pueden ser propiedades de la clase. Los que no sepáis qué es una función, una variable o una constante no os preocupéis, que lo veremos a su debido tiempo.
En cada aplicación que escribas en C# debes poner un método llamado Main, que además ha de ser public y static (veremos estos modificadores más adelante). No importa en qué clase de tu aplicación escribas el método Main, pero quédate con la copla: en todo programa escrito en C# debe haber un método Main, pues será el que busque el CLR para ejecutar tu aplicación. A partir de aquí, lo más aconsejable es escribir el método Main en una clase que se llame igual que el programa más las letras App. Por ejemplo, si es una calculadora, lo más recomendable es situar el método Main en una clase que se llame CalculadoraApp. Ahora bien, recuerda que esto no te lo exige el compilador, así que si pones el método Main en cualquier otra clase el programa funcionará.
Otra cosa importante a tener en cuenta es que C# distingue las mayúsculas de las minúsculas, de modo que una variable que se llame “Nombre” es distinta de otra que se llame “nombre”, y un método que se llame “Abrir” será distinto de otro que se llame “abrir”. Adaptarte a esto será lo que más te cueste si eres programador de Visual Basic. No obstante, verás que tiene algunas ventajas.
C# soporta la sobrecarga de métodos, es decir, que puedes escribir varios métodos en la misma clase que se llamen exactamente igual, pero recuerda que la lista de argumentos ha de ser diferente en cada uno de ellos, ya se diferencien en el número de argumentos o bien en el tipo de dato de dichos argumentos. Esto es algo que Visual Basic.NET también soporta (por fin), pero no sucedía así en las versiones anteriores de dicho lenguaje.
También soporta la sobrecarga de operadores y conversiones definidas por el usuario. Esto quiere decir que cuando diseñes una clase puedes modificar el comportamiento de varios de los operadores del lenguaje para que hagan cosas distintas de las que se esperan, y quiere decir también que si usas una clase diseñada por otro programador, uno o varios operadores pueden estar sobrecargados, por lo que es conveniente revisar la documentación de dicha clase antes de empezar a usarla, no sea que le intentes sumar algo, por ejemplo, y te haga cualquier cosa que no te esperas. De todos modos, cuando lleguemos al tema de la sobrecarga de operadores te daré algunos consejos sobre cuándo es apropiado usar esta técnica y cuándo puede ser contraproducente.
En C# no existen archivos de cabecera ni módulos de definición, así que, si programabas en C o C++, puedes olvidarte de la directiva #include cuando cuente tres: uno...dos...tres ¡YA! Si programabas en MODULA 2, puedes aplicarte el cuento con el FROM ... IMPORT, aunque esta vez no voy a contar. Si programabas en otro lenguaje no me preguntes, que no tengo ni idea. Si no sabías programar en ningún lenguaje, mejor que no te olvides de nada, que si no la liamos. En lugar de esto tenemos algo mucho más fácil y manejable: los espacios de nombres, de los cuales hablaremos en la próxima entrega.
Para terminar, puedes poner los comentarios a tu código de dos formas: // indica que es un comentario de una sola línea. /* ... comentario ... */ es un comentario de una o varias líneas. Observa el ejemplo:
// Esto es un comentario de una única línea
/* Esto es un comentario que consta de
varias líneas */
LOS ESPACIOS DE NOMBRES
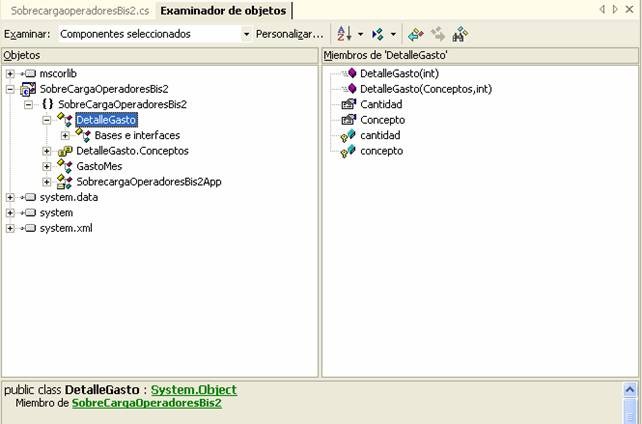
Los espacios de nombres son un modo sencillo y muy eficaz de tener absolutamente todas las clases perfectamente organizadas, tanto las que proporciona el .NET Framework como las que podamos escribir nosotros. Podemos verlo verdaderamente claro con echar un simple vistazo al explorador de objetos de Visual Studio.NET (menú Ver...Otras ventanas...Examinador de objetos, o bien la combinación de teclas Ctrl+Alt+J).
Lo que tenemos a la izquierda es toda la biblioteca de clases del .NET Framework. Como ves están completamente organizadas en árbol, de modo que toda ella está fuertemente estructurada. Además, fíjate bien en la rama que está parcialmente desplegada. No se trata de nada que esté dentro de la biblioteca de clases del .NET Framework, sino de una aplicación diseñada en C#. Por lo tanto, como ves, nosotros también podemos definir nuestros propios espacios de nombres.
Las ventajas principales de estos espacios de nombres son su fuerte estructuración y, sobre todo, la posibilidad de usar varias clases distintas con el mismo nombre en un mismo programa si los espacios de nombres son diferentes. No, no es el mismo perro con distinto collar. Es relativamente fácil que varios fabricantes de software den el mismo nombre a sus clases pues, al fin y al cabo, solemos basarnos en nuestro idioma para nombrarlas. Sin embargo es mucho menos probable que los espacios de nombres coincidan, sobre todo si se tiene la precaución de seguir las recomendaciones de Microsoft, que consisten en comenzar por llamar al espacio de nombres igual que se llama la compañía, más luego lo que sea. Por ejemplo, si mi compañía se llama NISU, y escribo un espacio de nombres con clases que realizan complejos cálculos para la navegación espacial, mi espacio de nombres podría llamarse NISUNavegacionEspacial. Si, después, IBM desarrolla una biblioteca similar, su espacio de nombres se llamaría IBMNavegacionEspacial (venga, hombre, échame una mano... imagínate que los de IBM hablan español). Aunque el nombre de mis clases coincida en gran número con los de las clases de IBM, cualquier desarrollador podría utilizar las dos sin problemas gracias a los espacios de nombres.
Definir un espacio de nombres es de lo más sencillo:
namespace NISUNavegacionEspacial
{
// Aquí van las clases del espacio de nombres
}
Por otro lado, ten presente que dentro de un mismo proyecto podemos definir tantos espacios de nombres como necesitemos.
Y si definir un espacio de nombres es sencillo, usarlo es más sencillo aún:
NISUNavegacionEspacial.Clase objeto = new NISUNavegacionEspacial.Clase(argumentos);
Efectivamente, se coloca primero el nombre del espacio de nombres y después, separado por un punto, el miembro de este espacio de nombres que vayamos a usar. No obstante, dado que los espacios de nombres están estructurados en árbol, pudiera ser que llegar a algún miembro requiera escribir demasiado código, pues hay que indicar toda la ruta completa:
NISUNavegacionEspacial.Propulsion.Combustibles.JP8 objeto = new
NISUNavegacionEspacial.Propulsion.Combustibles.JP8 (argumentos);
Ciertamente, escribir chorizos tan largos sólo para decir que quieres usar la clase JP8 puede resultar muy incómodo. Para situaciones como esta C# incorpora la directiva using. Para que os hagáis una idea, sería como cuando poníamos PATH = lista de rutas en nuestro viejo y querido MS-DOS. ¿Qué ocurría? Pues cuando escribíamos el nombre de un archivo ejecutable primero lo buscaba en el directorio donde estábamos posicionados. Si no lo encontraba aquí revisaba todas las rutas que se habían asignado al PATH. Si lo encontraba en alguna de estas rutas lo ejecutaba directamente, y si no lo encontraba nos saltaba un mensaje de error ¿Os acordáis del mensaje de error? “Comando o nombre de archivo incorrecto” (je je, qué tiempos aquellos...) Bueno, a lo que vamos, no me voy a poner nostálgico ahora... Básicamente, eso mismo hace la directiva using con los espacios de nombres: si utilizamos un nombre que no se encuentra en el espacio de nombres donde lo queremos usar, el compilador revisará todos aquellos que se hayan especificado con la directiva using. Si lo encuentra, pues qué bien, y si no lo encuentra nos lanza un mensaje de error. Qué te parece, tanto Windows, tanto .NET, tanta nueva tecnología... ¡y resulta que seguimos como en el DOS! Fuera de bromas, quiero recalcar que no equivale a la directiva #include de C, ni mucho menos. La directiva #include significaba que íbamos a usar funciones de un determinado archivo de cabecera. Si no se ponía, las funciones de dicho archivo, simplemente, no estaban disponibles. Sin embargo podemos usar cualquier miembro de los espacios de nombres sin necesidad de poner ninguna directiva using. Espero que haya quedado claro. Vamos con un ejemplo. Lo que habíamos puesto antes se podría haber hecho también de esta otra forma:
using NISUNavegacionEspacial.Propulsion.Combustibles;
...
JP8 objeto = new JP8 (argumentos);
De todos modos, no puedes usar la directiva using donde y como te de la gana. Fijo que los programadores de Visual Basic se han “colao”. La directiva using tampoco equivale al bloque With de Visual Basic pues, sencillamente, no es un bloque. Solamente puedes ponerla, o bien al principio del programa, con lo cual afectaría a todos los espacios de nombres que definas en dicho programa, o bien dentro de los espacios de nombres, pero siempre antes de cualquier definición de miembro de dicho espacio de nombres, con lo cual afectaría solamente a los miembros del espacio de nombres donde la has puesto. Veamos un ejemplo:
using System.Console;
namespace Espacio1
{
...
WriteLine(“Hola”);
...
}
namespace Espacio2
{
...
WriteLine(“Hola otra vez”)
...
}
o bien
namespace Espacio1
{
using System.Console;
...
WriteLine(“Hola”);
...
}
namespace Espacio2
{
...
WriteLine(“Hola otra vez”) // Aquí saltaría un error. using solo es efectivo para Espacio1
...
}
En el primer caso no saltaría ningún error, ya que WriteLine es un método static de la clase System.Console, y using afecta a los dos espacios de nombres (Espacio1 y Espacio2) al estar escrito al principio del programa. Sin embargo, en el segundo ejemplo el compilador nos avisaría de que no encuentra WriteLine en ninguno de los espacios de nombres, dado que using sólo es efectivo dentro de Espacio1 al estar escrito dentro de él. Por cierto, los tres puntos significan que por ahí hay más código, obviamente.
¿Y qué pasa si tengo dos clases que se llaman igual en distintos espacios de nombres? ¿No puedo poner using para abreviar? En este caso, lo mejor sería utilizar los alias, los cuales se definen tambén con using:
using NISU = NISUNavegacionEspacial; // A partir de aquí, NISU equivale a NISUNavegacionEspacial
using IBM = IBMNavegacionEspacial; // A partir de aquí, IBM equivale a IBMNavegacionEspacial
...
NISU.ModuloLunar modulo = new NISU.ModuloLunar();
IBM.ModuloLunar modulo2 = new IBM.ModuloLunar();
...
Se ve bien claro: el objeto modulo pertenecerá a la clase ModuloLunar del espacio de nobres NISUNavegacionEspacial, mientras que el objeto modulo2 pertenecerá a la clase ModuloLunar también, pero esta vez del espacio de nombres IBMNavegacionEspacial.
Para terminar ya con esto, que sepas que puedes poner tantas directivas using como estimes oportunas siempre que cumplas las reglas de colocación de las mismas.
LAS CLASES: UNIDADES BÁSICAS DE ESTRUCTURAMIENTO
Como dije en la entrega anterior, todo programa en C# se organiza en clases y estructuras. Las clases son, por lo tanto, la base fundamental de cualquier programa escrito en este lenguaje. Veamos cómo se construye una clase:
class NombreClase
{
// Aquí se codifican los miembros de la clase
}
Como puedes apreciar, es muy simple. Basta con poner la palabra class seguida del nombre de la clase y, a continuación, poner el signo de apertura de bloque "{" para empezar a codificar sus miembros. El fin de la clase se marca con el signo de cierre de bloque "}". Pero, claro, no todas las clases tienen por qué ser igualmente accesibles desde otra aplicación. Me explico: puede que necesites una clase que sólo se pueda usar por código que pertenezca al mismo ensamblado. En este caso, bastaría con poner el modificador de acceso internal delante de la palabra class o bien no poner nada, pues internal es el modificador de acceso por defecto para las clases:
Nota (25/Oct/07):
En C#, el modificador por defecto de las clases es
private, no
internal como se indica en este artículo.
Para más info:
Ámbitos predeterminados (si no se indica).
Gracias a Cesar Augusto Hernandez Mosquera por indicarme el gazapo.
internal class NombreClase
{
// Aquí se codifican los miembros de la clase
}
Si lo que quieres es una clase que sea accesible desde otros ensamblados, necesitarás que sea pública, usando el modificador de acceso public:
public class NombreClase
{
// Aquí se codifican los miembros de la clase
}
Ah, y no os apuréis, que ya trataremos los ensamblados más adelante (mucho más adelante).
INDICADORES: VARIABLES Y CONSTANTES
Los indicadores representan un determinado espacio de memoria reservado para almacenar un valor determinado, sea del tipo que sea (después hablaremos de los tipos en C#, pues creo que es mejor hacerlo cuando sepas para qué sirven). Por ejemplo, si quiero reservar memoria para almacenar el nombre de un cliente puedo declarar un indicador que se llame Nombre. Al hacer esto, el compilador reservará un espacio de memoria para que se pueda almacenar el dato. Este sería un caso típico de indicador variable, ya que su valor puede ser modificado una o varias veces durante la ejecución de un programa (ten en cuenta que antes de ejecutar el programa no sabremos nada sobre el cliente). Para declararlo hay que colocar previamente el tipo y después el nombre del indicador. Veámoslo:
class GestorClientesApp
{
public static void Main()
{
string Nombre; // Declaración de la variable nombre, que es de tipo string
Console.Write("¿Cómo se llama el cliente? ");
Nombre = Console.ReadLine();
Console.WriteLine("Mi cliente se llama {0}", Nombre);
}
}
En este sencillo programa, el compilador reservará memoria para la variable Nombre. En la ejecución del mismo primero preguntaría por el nombre del cliente y, después de haberlo escrito nosotros, nos diría cómo se llama. Algo así (en rojo está lo que hemos escrito nosotros durante la ejecución del programa):
¿Cómo se llama el cliente? Antonio
Mi cliente se llama Antonio
Date cuenta que para que el programa nos pueda decir cómo se llama el cliente no hemos usado el nombre literal (Antonio), ni la posición de memoria donde estaba este dato, sino simplemente hemos usado el indicador variable que habíamos definido para este propósito. De aquí en adelante, cuando hable de variables me estaré refiriendo a este tipo de indicadores.
También podemos inicializar el valor de una variable en el momento de declararla, sin que esto suponga un obstáculo para poder modificarlo después:
int num=10;
De otro lado tenemos los indicadores constantes (constantes en adelante). También hacen que el compilador reserve un espacio de memoria para almacenar un dato, pero en este caso ese dato es siempre el mismo y no se puede modificar durante la ejecución del programa. Además, para poder declararlo es necesario saber previamente qué valor ha de almacenar. Un ejemplo claro sería almacenar el valor de pi en una constante para no tener que poner el número en todas las partes donde lo podamos necesitar. Se declaran de un modo similar a las variables, aunque para las constantes es obligatorio decirles cuál será su valor, y este ha de ser una expresión constante. Basta con añadir la palabra const en la declaración. Vamos con un ejemplo:
using System;
namespace Circunferencia1
{
class CircunferenciaApp
{
public static void Main()
{
const double PI=3.1415926; // Esto es una constante
double Radio=4; // Esto es una variable
Console.WriteLine("El perímetro de una circunferencia de radio {0} es {1}", Radio,
2*PI*Radio);
Console.WriteLine("El área de un círculo de radio {0} es {1}", Radio,
PI*Math.Pow(Radio,2));
}
}
}
La salida en la consola de este programa sería la siguente:
El perímetro de una circunferencia de radio 4 es 25,1327408
El área de un círculo de radio 4 es 50,2654816
Como ves, en lugar de poner 2*3.1415926*Radio donde damos la circunferencia hemos puesto 2*PI*Radio, puesto que el valor constante por el que debemos multiplicar (el valor de pi en este caso) lo hemos almacenado en una constante, haciendo así el código más cómodo y fácil de leer.
Los indicadores, al igual que las clases, también tienen modificadores de acceso. Si se pone, ha de colocarse en primer lugar. Si no se pone, el compilador entenderá que es private. Dichos modificadores son:
MODIFICADOR | COMPORTAMIENTO |
public | Hace que el indicador sea accesible desde otras clases. |
protected | Hace que el indicador sea accesible desde otras clases derivadas de aquella en la que está declarado, pero no desde el cliente |
private | Hace que el indicador solo sea accesible desde la clase donde está declarado. Este es el modificador de acceso por omisión. |
internal | Hace que el indicador solo sea accesible por los miembros del ensamblaje actual. |
Un caso de variable con nivel de acceso protected, por ejemplo, sería:
protected int Variable;
Otro asunto importante a tener en cuenta es que, cuando se declara un indicador dentro de un bloque que no es el de una clase o estructura, este indicador será siempre privado para ese bloque, de modo que no será accesible fuera del mismo (no te preocupes mucho si no acabas de entender esto. Lo verás mucho más claro cuando empecemos con los distintos tipos de bloques de código. De momento me basta con que tengas una vaga idea de lo que quiero decir).
EL SISTEMA DE TIPOS DE C#
El sistema de tipos suele ser la parte más importante de cualquier lenguaje de programación. El uso correcto de los distintos tipos de datos es algo fundamental para que una aplicación sea eficiente con el menor consumo posible de recursos, y esto es algo que se tiende a olvidar con demasiada frecuencia. Todo tiene su explicación: antiguamente los recursos de los equipos eran muy limitados, por lo que había que tener mucho cuidado a la hora de desarrollar una aplicación para que esta no sobrepasara los recursos disponibles. Actualmente se produce el efecto contrario: los equipos son muy rápidos y potentes, lo cual hace que los programadores se relajen, a veces demasiado, y no se preocupen por economizar medios. Esta tendencia puede provocar un efecto demoledor: aplicaciones terriblemente lentas, inestables y muy poco eficientes.
Bien, después del sermón, vamos con el meollo de la cuestión. Actualmente, muchos de los lenguajes orientados a objetos proporcionan los tipos agrupándolos de dos formas: los tipos primitivos del lenguaje, como números o cadenas, y el resto de tipos creados a partir de clases. Esto genera muchas dificultades, ya que los tipos primitivos no son y no pueden tratarse como objetos, es decir, no se pueden derivar y no tienen nada que ver unos con otros. Sin embargo, en C# (más propiamente en .NET Framework) contamos con un sistema de tipos unificado, el CTS (Common Type System), que proporciona todos los tipos de datos como clases derivadas de la clase de base System.Object (incluso los literales pueden tratarse como objetos). Sin embargo, el hacer que todos los datos que ha de manejar un programa sean objetos puede provocar que baje el rendimiento de la aplicación. Para solventar este problema, .NET Framework divide los tipos en dos grandes grupos: los tipos valor y los tipos referencia.
Cuando se declarara variable que es de un tipo valor se está reservando un espacio de memoria en la pila para que almacene los datos reales que contiene esta variable. Por ejemplo en la declaración:
int num =10;
Se está reservando un espacio de 32 bits en la pila (una variable de tipo int es un objeto de la clase System.Int32), en los que se almacena el 10, que es lo que vale la variable. Esto hace que la variable num se pueda tratar directamente como si fuera de un tipo primitivo en lugar de un objeto, mejorando notablemente el rendimento. Como consecuencia, una variable de tipo valor nunca puede contener null (referencia nula). ¿Cómo? ¿Que qué es eso de una pila? ¡Vaya!, tienes razón. Tengo la mala costumbre de querer construir la casa por el tejado. Déjame que te cuente algo de cómo se distribuye la memoria y luego sigo.
Durante la ejecución de todo programa, la memoria se distribuye en tres bloques: la pila, el montón (traducción libre o, incluso, “libertina” de heap) y la memoria global. La pila es una estructura en la que los elementos se van apilando (por eso, curiosamente, se llama pila), de modo que el último elemento en entrar en la pila es el primero en salir (estructura LIFO, o sea, Last In First Out). A ver si me explico mejor: Cuando haces una invocación a un método, en la pila se van almacenando la dirección de retorno (para que se pueda volver después de la ejecución del método) y las variables privadas del método invocado. Cuando dicho método termina las variables privadas del mismo se quitan de la pila ya que no se van utilizar más y, posteriormente, la dirección de retorno, ya que la ejecución ha retornado. El montón es un bloque de memoria contiguo en el cual la memoria no se reserva en un orden determinado como en la pila, sino que se va reservando aleatoriamente según se va necesitando. Cuando el programa requiere un bloque del montón, este se sustrae y se retorna un puntero al principio del mismo. Un puntero es, para que me entiendas, algo que apunta a una dirección de memoria. La memoria global es el resto de memoria de la máquina que no está asignada ni a la pila ni al montón, y es donde se colocan el método main y las funciones que éste invocará. ¿Vale? Seguimos.
En el caso de una variable que sea de un tipo referencia, lo que se reserva es un espacio de memoria en el montón para almacenar el valor, pero lo que se devuelve internamente es una referencia al objeto, es decir, un puntero a la dirección de memoria que se ha reservado. No te alarmes: los tipos referencia son punteros de tipo seguro, es decir, siempre van a apuntar a lo que se espera que apunten. En este caso, evidentemente, una variable de un tipo referencia sí puede contener una referencia nula (null).
Entonces, si los tipos valor se van a tratar como tipos primitivos, ¿para qué se han liado tanto la manta a la cabeza? Pues porque una variable de un tipo valor funcionará como un tipo primitivo siempre que sea necesario, pero podrá funcionar también como un tipo referencia, es decir como un objeto, cuando se necesite que sea un objeto. Un ejemplo claro sería un método que necesite aceptar un argumento de cualquier tipo: en este caso bastaría con que dicho argumento fuera de la clase object; el método manejará el valor como si fuera un objeto, pero si le hemos pasado un valor int, este ocupa únicamente 32 bits en la pila. Hacer esto en otros lenguajes, como Java, es imposible, dado que los tipos primitivos en Java no son objetos.
Aquí tienes la tabla de los tipos que puedes manejar en C# (mejor dicho, en todos los lenguajes basados en el CLS), con su equivalente en el CTS (Common Type System).
RESUMEN DEL SISTEMA DE TIPOS
Tipo CTS | Alias C# | Descripción | Valores que acepta |
System.Object | object | Clase base de todos los tipos del CTS | Cualquier objeto |
System.String | string | Cadenas de caracteres | Cualquier cadena |
System.SByte | sbyte | Byte con signo | Desde -128 hasta 127 |
System.Byte | byte | Byte sin signo | Desde 0 hasta 255 |
System.Int16 | short | | Desde -32.768 hasta 32.767 |
System.UInt16 | ushort | Enteros de 2 bytes sin signo | Desde 0 hasta 65.535 |
System.Int32 | int | Enteros de 4 bytes con signo | Desde -2.147.483.648 hasta 2.147.483.647 |
System.UInt32 | uint | Enteros de 4 bytes sin signo | Desde 0 hasta 4.294.967.295 |
System.Int64 | long | Enteros de 8 bytes con signo | Desde -9.223.372.036.854.775.808 hasta 9.223.372.036.854.775.807 |
System.UInt64 | ulong | Enteros de 8 bytes sin signo | Desde 0 Hasta 18.446.744.073.709.551.615 |
System.Char | char | Caracteres Unicode de 2 bytes | Desde 0 hasta 65.535 |
System.Single | float | Valor de coma flotante de 4 bytes | Desde 1,5E-45 hasta 3,4E+38 |
System.Double | double | Valor de coma flotante de 8 bytes | Desde 5E-324 hasta 1,7E+308 |
System.Boolean | bool | Verdadero/falso | true ó false |
System.Decimal | decimal | Valor de coma flotante de 16 bytes (tiene 28-29 dígitos de precisión) | Desde 1E-28 hasta 7,9E+28 |
Aunque ya lo has visto antes, aún no lo hemos explicado: para declarar una variable de uno de estos tipos en C# hay que colocar primero el tipo del CTS o bien el alias que le corresponde en C#, después el nombre de la variable y después, opcionalmente, asignarle su valor:
System.Int32 num=10;
int num=10;
La variable num sería de la clase System.Int32 en ambos casos: en el primero hemos usado el nombre de la clase tal y como está en el CTS, y en el segundo hemos usado el alias para C#. No olvides que la asignación del valor en la declaración es opcional. En todos los lenguajes que cumplen las especificaciones del CLS se usan los mismos tipos de datos, es decir, los tipos del CTS, aunque cada lenguaje tiene sus alias específicos. Por ejemplo, la variable num de tipo int en Visual Basic sería:
Dim num As System.Int32 = 10
Dim num As Integer = 10
En cualquier caso, y para cualquier lenguaje que cumpla las especificaciones del CLS, los tipos son los mismos.
Si no has programado nunca es posible que a estas alturas tengas un importante jaleo mental con todo esto. ¿Para qué tantos tipos? ¿Es que no es lo mismo el número 100 en una variable de tipo int que en una de tipo byte, o short, o long, o decimal? ¿Qué es eso de la coma flotante? ¿Qué es eso de las cadenas? ¿Qué son los caracteres unicode? ¡Qué me estás contandooooo! Bueno, trataré de irte dando respuestas, no te preocupes.
Todos los tipos son necesarios en aras de una mayor eficiencia. Realmente, podríamos ahorrarnos todos los tipos numéricos y quedarnos, por ejemplo, con el tipo Decimal, pero si hacemos esto cualquier número que quisiéramos meter en una variable ocuparía 16 bytes de memoria, lo cual supone un enorme desperdicio y un excesivo consumo de recursos que, por otra parte, es absolutamente innecesario. Si sabemos que el valor de una variable va a ser siempre entero y no va a exceder de, por ejemplo, 10.000, nos bastaría un valor de tipo short, y si el valor va a ser siempre positivo, nos sobra con un tipo ushort, ya que estos ocupan únicamente 2 bytes de memoria, en lugar de 16 como las variables de tipo decimal. Por lo tanto, no es lo mismo el número 100 en una variable de tipo short que en una de otro tipo, porque cada uno consume una cantidad diferente de memoria. En resumen: hay que ajustar lo máximo posible el tipo de las variables a los posibles valores que estas vayan a almacenar. Meter valores pequeños en variables con mucha capacidad es como usar un almacén de 200 metros cuadrados sólo para guardar una pluma. ¿Para qué, si basta con un pequeño estuche? Para asignar un valor numérico a una variable numérica basta con igualarla a dicho valor:
int num=10;
Un tipo que admite valores de coma flotante admite valores con un número de decimales que no está fijado previamente, es decir, números enteros, o con un decimal, o con dos, o con diez... Por eso se dice que la coma es flotante, porque no está siempre en la misma posición con respecto al número de decimales (el separador decimal en el código siempre es el punto).
double num=10.75;
double num=10.7508;
Las cadenas son una consecución de caracteres, ya sean numéricos, alfabéticos o alfanuméricos. A ver si me explico mejor. La expresión 1 + 2 daría como resultado 3, ya que simplemente hay que hacer la suma. Sin embargo, la expresión “1” + “2” daría como resultado “12”, ya que ni el uno ni el dos van a ser considerados números sino cadenas de caracteres al estar entre comillas. Tampoco el resultado se considera un número, sino también una cadena, es decir, el resultado de unir las dos anteriores o, lo que es lo mismo, la concatenación de las otras cadenas (“1” y “2”). Por lo tanto, cuando se va a asignar un valor literal a una variable de tipo string hay que colocar dicho literal entre comillas:
string mensaje = “Buenos días”;
Los caracteres unicode es un conjunto de caracteres de dos bytes. ¿Que te has quedado igual? Vaaaaale, voooooy. Hasta hace relativamente poco en occidente se estaba utilizando el conjunto de caracteres ANSI, que constaba de 256 caracteres que ocupaban un byte. ¿Qué pasaba? Que este conjunto de caracteres se quedaba muy corto en oriente, por lo que ellos usaban el conjunto unicode, que consta de 65.536 caracteres. Lo que se pretende con .NET es que, a partir de ahora, todos usemos el mismo conjunto de caracteres, es decir, el conjunto unicode. Por eso, todas las variables de tipo char almacenan un carácter unicode.
¿Y las fechas? Para las fechas también hay una clase, aunque en C# no hay ningún alias para estos datos. Es la clase System.DateTime:
System.DateTime fecha;
Una vez conocido todo esto, es importante también hablar de las conversiones. A menudo necesitarás efectuar operaciones matemáticas con variables de distintos tipos. Por ejemplo, puede que necesites sumar una variable de tipo int con otra de tipo double e introducir el valor en una variable de tipo decimal. Para poder hacer esto necesitas convertir los tipos. Pues bien, para convertir una expresión a un tipo definido basta con poner delante de la misma el nombre del tipo entre paréntesis. Por ejemplo, (int) 10.78 devolvería 10, es decir, 10.78 como tipo int. Si ponemos (int) 4.5 * 3 el resultado sería 12, ya que (int) afecta únicamente al valor 4.5, de modo que lo convierte en 4 y después lo multiplica por 3. Si, por el contrario, usamos la expresión (int) (4.5 * 3), el resultado sería 13, ya que en primer lugar hace la multiplicación que está dentro del paréntesis (cuyo resultado es 13.5) y después convierte ese valor en un tipo int. Hay que tener un cuidado especial con las conversiones: no podemos convertir lo que nos de la gana en lo que nos apetezca, ya que algunas converisones no son válidas: por ejemplo, no podemos convertir una cadena en un tipo numérico:
int a = (int) cadena; // Error. Una cadena no se puede convertir a número
Para este caso necesitaríamos hacer uso de los métodos de conversión que proporcionan cada una de las clases del .NET Framework para los distintos tipos de datos:
int a = System.Int32.Parse(cadena); // Así sí
continuara[...]
fuente: http://www.elguille.info/NET/cursoCSharpErik/Entrega3/Entrega3.htm